Vsi zgledi uporabljajo programe iz paketa poppler oz. poppler-tools. Na Linuxovih distribucijah so velikokrat že nameščeni. Repology.
Tu pride v poštev orodje pdftoppm. Elemente strani splošči in izvozi v poljuben format (PNG, JPEG in drugi). Meni pride prav pri izvažanju strani skeniranih knjig, saj lahko sočasno izberem izvoz lihih strani, številsko območje strani, koordinate za izrez in resolucijo.
$ pdftoppm -f 150 -l 343 -o -r 300 -jpeg -progress \
-x 120 -W 1845 -y 165 -H 2690 \
"Upmark - Die Architectur der Renaissance in Schweden.pdf" upmark
Po vrsti: -f poda začetno stran, -l končno. -o vzame le lihe strani (-e sode), -r poda resolucijo izvožene strani (enota DPI), -jpeg določi izhodni format, -progress pa sproti obvešča, katero stran obdeluje.
Za obrezovanje služijo 4 argumenti:
-x in -y podata odmik od zgornjega levega kota-W in -H pa širino in višino, začenši na koordinatah, podanih z -x/-y (oz. v izhodišču, če nista podani)Zadnji argument je osnova datotečnega imena za vse pretvorjene slike, ki jim bo program pripel številko strani (upmark-151.jpg, upmark-153.jpg …). Svetujem začetni preizkus na majhnem številu strani, da se ugotovijo pravi parametri obrezovanja in resolucije.
Podrobnosti: pdftoppm -help oz. man pdftoppm.
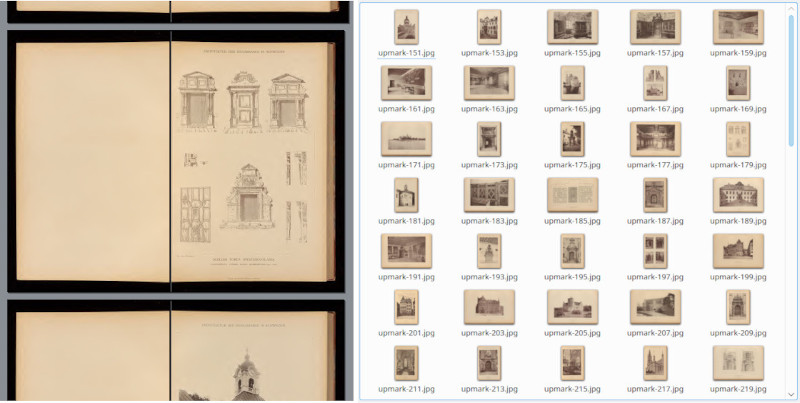
Pregledovanje skeniranih dokumentov z več sto stranmi slik je zamudno zaradi počasnega nalaganja in polovice praznih strani. Izvoz v slike z možnostjo hitrega predogleda je zato dobrodošel.
Če ne želimo izvažati celotnih strani, temveč le slike v dokumentu, uporabimo pdfimages. Uporaba je podobna kot pri pdftoppm:
$ pdfimages -f 18 -l 28 -j -p "Anonimni modernizem Trnovo.pdf" trnovo
-f in -l sta za območje strani, -j izvozi v JPEG, -p pa datotečnemu imenu doda številko strani dokumenta, kjer se je slika nahajala. Na koncu je koren datotečnega imena. Sodih/lihih strani se ne da izbirati.
Podrobnosti: pdfimages -help oz. man pdfimages.
Ima pa pdfimages nekatere omejitve:

Zato pri nekaterih celostranskih skeniranih dokumentih uporabljam pdftoppm.